This month I started looking into adding a cache to your application and came across the problem of adding and removing cache instances from your application efficiently.
Problem
Let’s assume you have a web application that’s running on multiple servers. To help speed up queries, you add a cache to store data accessed often by your application. Before calling the database for a piece of information, you first check if it exists in the cache. As you gain more users, one cache instance is too small to provide a significant performance boost. In this case, you add more cache instances to your server to cache more information.
But now, you have to check every cache instance to see if it contains a key. It would be easier if you knew which cache instance has the key beforehand.
Hashing
You can use hashing to determine which cache instance to save the key in. Compute hash(key) % N where hash is some hashing function and N is the number of cache instances. This function returns a number between 0 and N where each number refers to a cache instance. Thus you can map keys to cache instances. To check if a key exists in the cache, hash the key to get the cache instance and only check if that instance has the key. This strategy enables you to have multiple cache instances while keeping lookup efficient.
However, what happens if a cache instance crashes? The cache instance will be unavailable, and you will lose the cached data. In future queries, you will need to recache the data in a different cache instance. The only problem is that the value of N in (hash(key) % N) has changed. All your keys will map to a new cache instance. A key that maps to server:A now maps to server:B even though only server:C is unavailable. This increases cache misses across all cache instances even if one cache instance is unavailable. Ideally, we would only want to remap the keys for the unavailable server.
Consistent Hashing
Consistent hashing is a strategy to map keys to cache instances but allows cache instances to be added or removed from the list of available instances.
Consistent hashing works by imagining a circle. Each key and cache instance is assigned a corresponding point on this circle. To determine which cache instance to add a key to, we map the key to the closest cache on the circle going in a clockwise direction.
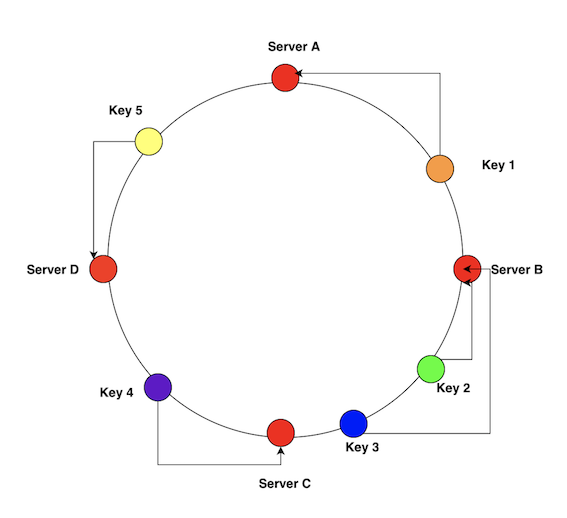
Programmatically, consistent hashing is simple to implement. We map each of our cache servers to some integer using a hash function. Here, the hash represents the point on the circle for the cache.
1
2
3
4
5
6
7
8
9
10
def add_node(node)
hash = hash_value(node)
hash_to_node[hash] = node
puts "Nodes map to #{@hash_to_node}"
end
def hash_value(node)
Digest::SHA256.digest(node).sum % 360
end
In the code above, we keep track of the mapping of hashes to nodes in hash_to_node.
To determine which cache instance to add a key to, we hash the key ie we find the corresponding point on the circle. Then we find the cache that hashes to a number greater than the key’s hash. This is effectively the cache that is closest to the key’s hash.
1
2
3
4
5
6
7
8
9
10
11
12
13
def find_cache(key)
hash = hash_value(key)
puts "#{key} hashes to #{hash}"
node_hash = closest_node_hash(hash)
node = hash_to_node[node_hash]
puts "#{key} maps to #{node}"
end
def closest_node_hash(key)
@hash_to_node.keys.sort.bsearch { |server| server >= key } || @hash_to_node.keys.sort.first
end
In closest_node_hash(key), we sort the cache instance hashes. Then we do a binary search (bsearch) to find the integer with a value greater than our hashed key.
If a value is not found, we return the first cache in the list. This emulates a circle since we “wrap” around to the beginning of the list.
Once we have the hash that is greater than the key, we get the corresponding cache instance. This is the cache we should add the key to.
We now have a consistent way to map our keys to cache instances.
Adding and Removing Nodes
Now let’s test what happens when you add or remove a cache instance. Let’s run this code on a set of keys to see what the mapping looks like:
1
2
3
4
5
6
7
8
9
10
11
12
13
Nodes map to {213=>"server:A", 154=>"server:B", 331=>"server:C"}
a hashes to 319
a maps to server:C
b hashes to 65
b maps to server:B
z hashes to 284
z maps to server:C
hello hashes to 165
hello maps to server:A
As you can see, the keys are distributed among the three cache instances.
Now, let’s add a node to our list and run it again.
1
2
3
4
5
6
7
8
9
10
11
12
13
Nodes map to {213=>"server:A", 154=>"server:B", 331=>"server:C", 301=>"server:B1"}
a hashes to 319
a maps to server:C
b hashes to 65
b maps to server:B
z hashes to 284
z maps to server:B1
hello hashes to 165
hello maps to server:A
When we add a server, only a small subset of keys get remapped to the new instance. Thus, only a small subset of keys will experience a cache miss as they get moved to a new cache. This is because the mapping depends on which node is “closest” to the key. When you add a new server, the closest server does not change for most keys. Thus the mapping for most of the keys remains consistent.
Now, let’s remove server:B from the list and see what happens.
1
2
3
4
5
6
7
8
9
10
11
12
13
Nodes map to {213=>"server:A", 331=>"server:C", 301=>"server:B1"}
a hashes to 319
a maps to server:C
b hashes to 65
b maps to server:A
z hashes to 284
z maps to server:B1
hello hashes to 165
hello maps to server:A
Only keys that mapped to server:B need to be remapped. All the other keys remain the same as their “closest” server has not changed.
As you can see, consistent hashing makes scaling our cache instances easier. Cache instances can be added and removed without having to remap all the keys.
As nodes are added and removed, the distribution of the keys can be uneven between the servers. In this case, we can add “fake” nodes which map to an existing server. For example, we can add another node for server A in the list. This will cause some keys to get remapped to server A and even out the distribution of keys.
Conclusion
I used caches in this blog post for a practical application of this hashing strategy. However, consistent hashing can be applied anytime you want to divide a set of keys across multiple nodes. For example, in peer-to-peer networks or a load balancer. My favorite part of learning about consistent hashing was seeing how a hash table can be modified to work in a more distributed way.
Code
You can find the complete implementation of the consistent hashing code on Github.