This month I started looking into system design patterns for scaling and application. I started off by learning about message queues: what are they and why are the useful?
The Problem
In a typical web application, a client sends a request to a server that processes it and returns a response. For example, the client may request a list of products. The server would query the database for the list of products and return the list. As the number of requests increases, one server can not handle all the requests. Some clients will be unable to connect with the server as it is unavailable. In this case, you can horizontally scale the application. You buy more servers for the application so that you can handle the increased load.
Now imagine, some requests are computationally expensive. For example, they need to generate a large report that uses a lot of CPU and takes many seconds to run. While generating reports, the server is unable to process other requests from clients.
One solution could be to buy even more servers to run your application. This can be expensive and wasteful. Say the report generation requests are more likely at the end of a month. Then for most of the month, you will have extra servers you don’t need. The additional servers are only required when there is an increased load from generating reports.
Synchronous Vs Asynchronous
We can solve this problem by changing how we think about processing requests. Currently, the client sends a request and then waits for a response from the server. The client is stuck waiting for many seconds while the server generates the report. The client needs a response from the server, but that response does not have to be the final report. Instead, the server can send a response that acknowledges the request for the report without returning the report. Then, it can process the request for the report asynchronously in the background. Once the report generates, the server can send an email to the client and let it know the report is complete.
By moving to asynchronous computation, we reduce the response time for the client. Instead of waiting for a response from the server, the client can complete other tasks. From a user’s perspective, they clicked a button and got a message that the report is being generated. The user can now do other things on the site while the report is generating.
By making the report generation asynchronous, the server can respond to more requests. Yet, what happens if the server gets a lot of requests to generate a report? It will try to generate all the reports in the background. The server will be doing too much background work and will slow down or run out of memory.
Queue
A server should only process one or two reports in the background at a time. If more requests for a report come in, they can be added to a report queue. Once a report is generated, the server can start generating the next report in the queue. This way, all the reports will eventually be generated without overwhelming the server.
This approach is better, but where is this queue stored? One solution is to store it on the server. However, this could lead to an unequal distribution of report generation requests. A server with a larger queue will take longer to generate reports compared to servers with smaller queues.
A better solution is to have a shared queue for all the servers. A set of servers can respond to requests and add tasks to the queue. The tasks could be any task we want to offload from the request servers. For example, sending emails or uploading a file to the cloud). Another set of servers can process background jobs currently in the queue. In this case, the queue would be a persistent data store (database, Redis cache, etc) that all servers can access.
This idea is known as a task queue (sometimes called a message queue).
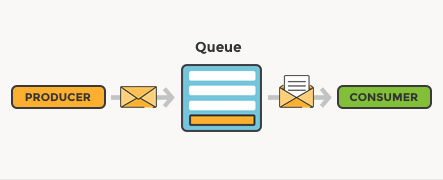
Task Queues
Task queues enable multiple systems to communicate with each other. One system acts as a producer and will add tasks to the queue. Another system is a consumer and processes the tasks in the queue and actions on them. In this case, the server handling requests is the producer which adds tasks to the queue. The servers which process the tasks are the consumers.
A task queue has many benefits. First, a producer and consumer never have to communicate with each other directly. The producers do not make an API call to the consumer to let them know of an event. Producers only need access to the queue. A producer can add a task to the queue even if none of the consumers are online. Once the consumers are back online, they would start processing that tasks in the queue.
Furthermore, the producers and consumers can scale independently. As the number of tasks increases, you can add more consumers without increasing the number of producers.
However, one downside to task queues (and asynchronous processes) is that the order of execution is no longer linear. You can’t guarantee the order the tasks run in. If some tasks depend on others completing first, the task queue logic becomes more complex.
Conclusion
As your application grows, offloading certain tasks to a message queue is a great way to scale your application. This blog post only touches the surfaces of tasks queues. Message queue software, such as RabbitMQ, has a lot of built-in functionality for managing message queues. They also allow you to implement other patterns with your message queue such as the publisher-subscriber pattern.